DIGITALOCEAN
AI Agent Evaluations
An agent evaluation layer to help users understand agent behavior and troubleshoot performance.
TL;DR
Starting from API and product documents, I designed DigitalOcean’s AI Agent Evaluation product suite, which allows users to create test cases, evaluate agents against industry standard metrics, see scores, and troubleshoot agent behavior. From 0 to GA (MVP) in less than 3 months.
The opportunity
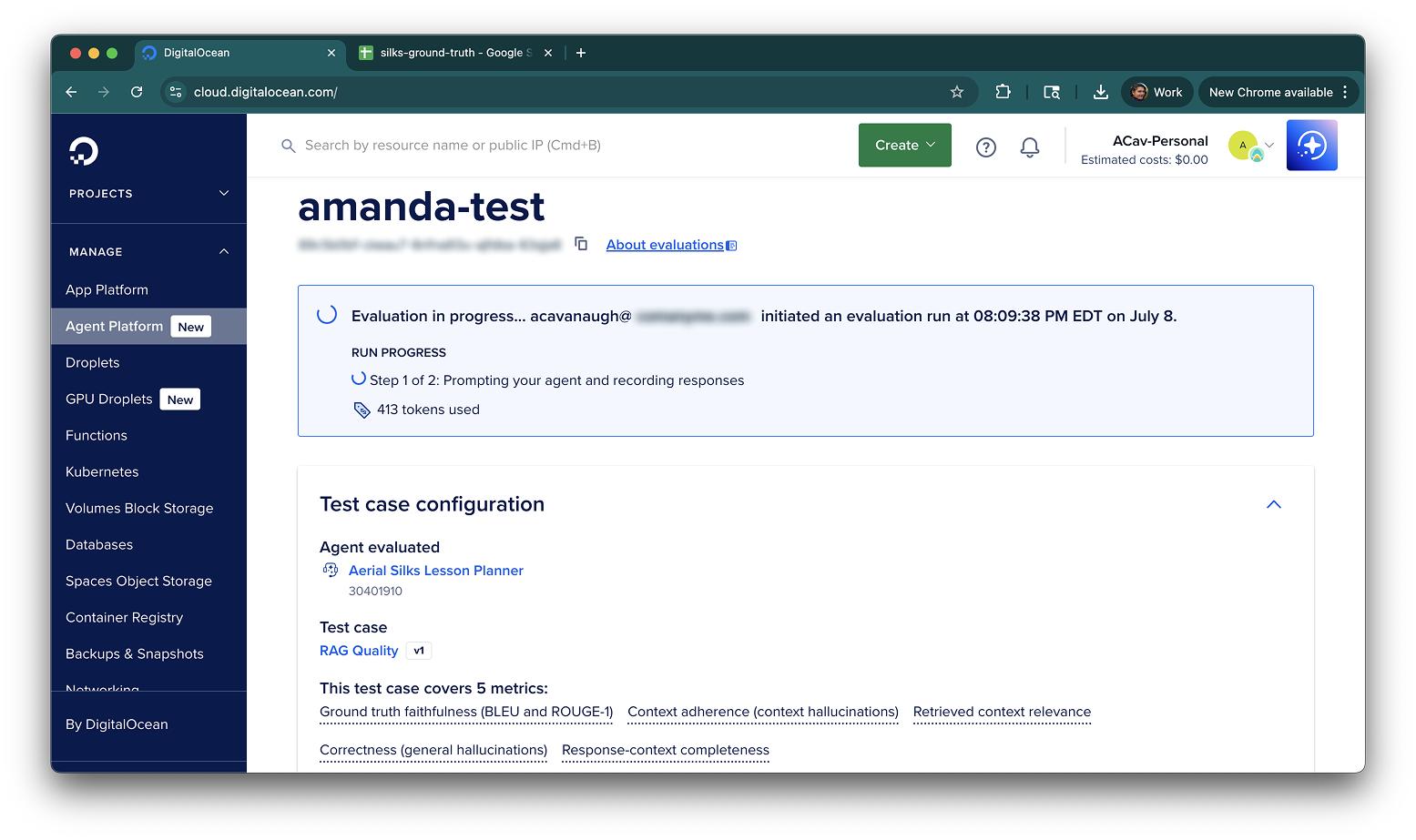
Is my agent behaving the way I want it to, and if it’s not, what can I do to make it behave the way I want it to behave?
A lot of the tools on the market in mid-2024 were focused on model evaluation. But model evaluation and agent evaluation are not the same: the metrics sometimes overlap but in general, agent evaluation is less about model performance itself and more about the agentic system as a whole behaving in a certain way. In our platform’s case, we do not support users bringing their own trained models, nor do we offer a full breadth of model customization, so most of what users can control in regards to the model are the basics: top p, temperature, max tokens, and some retrieval settings for RAG pipelines.
For RAG-based agents, which are agents that reference context from a knowledge base or other source that is not generally available in the agent’s model’s foundational training corpus, evaluations can help users:
identify if the RAG pipeline is working, period
troubleshoot data sources content
determining if the agent response is correct based on the context provided
There are several other agent-quality focused metrics that expand beyond the boundaries of typical “model evaluation” contexts that answer the questions:
“Is my agent following its instructions?”
“Is my agent hallucinating information that’s not in its context, or just flat out wrong?”
And some model/agent crossover metrics that answer questions like, “Is the model I chose a good fit for this agent’s scope?”
Back in September 2024, when DigitalOcean’s GenAI Platform (now GradientAI Platform, heretofore “our” or “the platform”) was still in private beta, our PM, eng team and I gathered with our user research partner to define out what trust looked like for AI agent builders.
For our users in 2024, trust was essentially a mix of ✨ vibes ✨ and some quantitative measurement in a few key areas, dominated by the handful of model evaluation tools on the market.
Our users cared about key metrics focused on “can I get sued because of what this thing says?” and “is this thing giving the right answers?”
For us, our ideal user outcome helped users answer this key question:
Model versus agent evaluation
Discovery Phase (part I)
As I took on the discovery for this project in 2024, I dug into the user research we had, and with the help of a researcher assigned to our team, went through a few rounds of interviews with our private and later public preview users to understand their agent development lifecycle.
We wanted to know where evaluations fell in their order of operations, if evaluations were a signal for production readiness, what “ready” or “trustworthy” felt like from both a qualitative and quantitative standpoint, and what their top priority questions were in order to trust their agent output.
-
Survey (sent out to all private and public preview users, as well as non-platform users with AI/ML workloads), qualitative interviews over Meet
-
Have users outline their agent development lifecycle, ask probing questions about timeline, critical questions, and what would give them a signal that their agent was trustworthy enough to put into production.
-
Evaluations would/should happen periodically through agent development lifecycle, with focus on different elements of the agent experience
early evaluations will focus on refining the model fit, agent instructions (system prompt), and general agent quality.
Later rounds will focus on content quality - RAG pipeline quality, tool calling quality.
Final rounds will be polish and gotchas that can be solved with additional tooling - focus on security and safety, covering toxicity and bias, PII and other security leaks, prompt injection attacks, and more.
Early stage design (Part I)
In 2024, we were planning on partnering with a small, evaluations-focused startup to serve as the backend for our evaluations experience. They had a robust documentation library outlining their metrics, and an API I could toy with to understand how we would use their API to inform our experience.
From their API and metrics docs, I outlined an initial pass at the evaluation framework we’d be testing with our users. Our evaluations platform partner had a very trust-forward approach to their metrics, with a heavy focus on putting together dimensions of trust within which their metrics were grouped. I generally found this approach to resonate with our users based on what we heard during research efforts, though I did have some concerns that their metrics were too rigorous for the maturity our users were at.
At about this time, the team realized that our users were not at the maturity level yet to need evaluations in the state we were going to be able to offer them, and the platform had higher priority tablestakes needs that were more important to tackle than evaluations.
So, after a few weeks of design work to hash out a content strategy and architecture approach for DigitalOcean’s agent evaluations experience, I tucked that Figma file to bed and moved onto other work leading up to our big public preview release.
⏸ Evaluations UX work paused Oct ‘24 to Apr ‘25 ⏯Discovery Phase (part II)
At a team offsite at the end of March 2025, evaluations were back on the table. This time, the engineering team, ML research team, and myself were asked to evaluate a few other potential partners to service the evaluations backend. The original partner was still in the running, but in the six months between when we paused on evaluations and picked it back up again, new competitors had entered the market with promising offerings.
We were also considering building the backend in-house, but with a “due date” of July 9, 2025 looming, we ultimately decided that buy/partner was going to be our most likely path to success.
I had about 3 days to do these evaluations, mostly relying on the product and API docs, as I wasn’t feeling competent enough to figure out how to implement each of the potential partners’ platforms with one of my own agents, and most of their UIs did not have parity with their API experience.
Regardless, we landed on a new provider and I immediately set off determining next steps.
Determine the object model
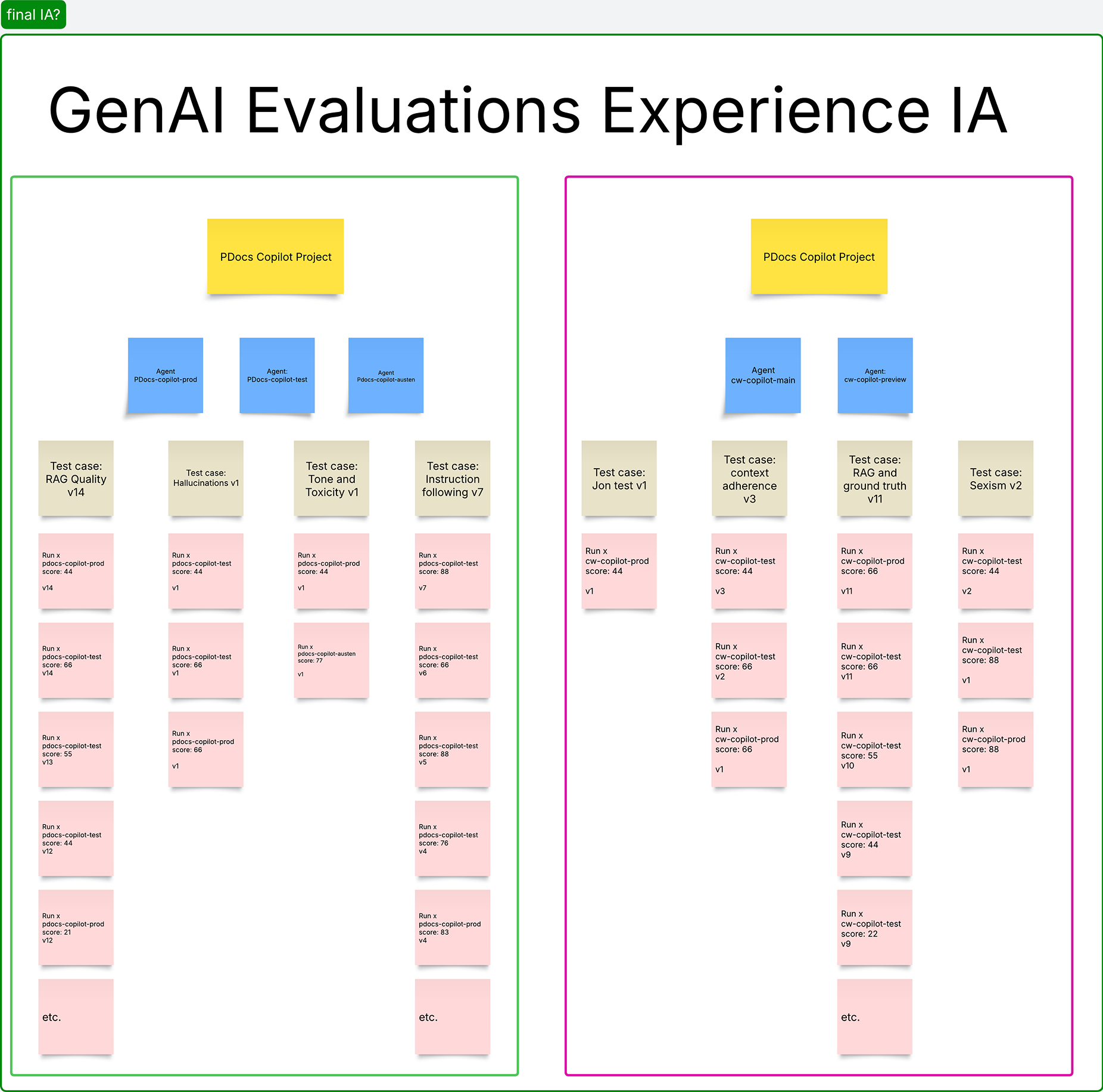
Within the GradientAI agent platform, I had planned on evaluations living as both their own entity, and as belonging to individual agents.
There would be evaluation templates, later renamed test cases, which were a combination of: name, metrics, dataset, pass/fail threshold. A test case could be run against any agent. A user could go to the list of test cases and see all runs across all agents under that test case, or go to a specific agent and see only runs for that agent, across all test cases.
Initially scoped in and later scoped out were user-managed datasets, which were assigned to test cases but could be versioned to allow for both dataset and test case evolution as users narrowed down ways to improve their agent output quality.
Enter: workspaces
As a part of the object modeling work, we started seeing a pattern in how users were organizing their agents on the platform. At the time, we did not offer a mechanism for users to group agents meaningfully. And because we do not support sandbox environments for agent testing, users who were at the maturity level to need to test out multiple agent configurations were creating multiple agents with slightly different configurations.
Evaluations would be used to evaluate the different versions of these agents, and help users understand and compare configuration outcomes to then determine what was a best fit for promotion to “production ready”.
Creating a grouping mechanism to allow users to not only group agents, but also create and manage test cases specific to these agents, led to the genesis of Agent Workspaces, a brand new information architecture model that required a complete reimagining of the platform IA.
Yes, we did in fact do that and deliver evals all in one release. Talk about a wild time.
Design cycles (part II)
The user-content relationship
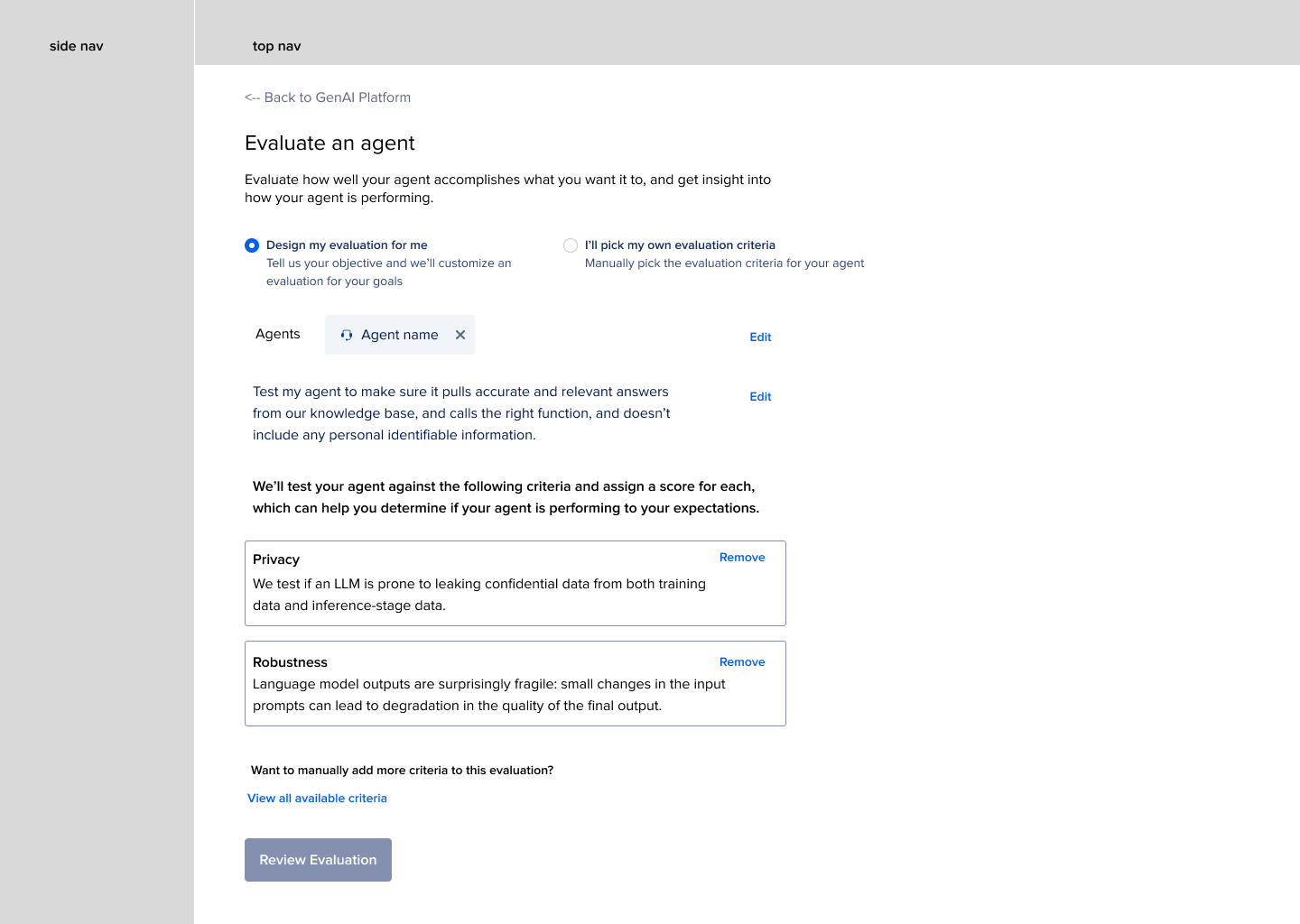
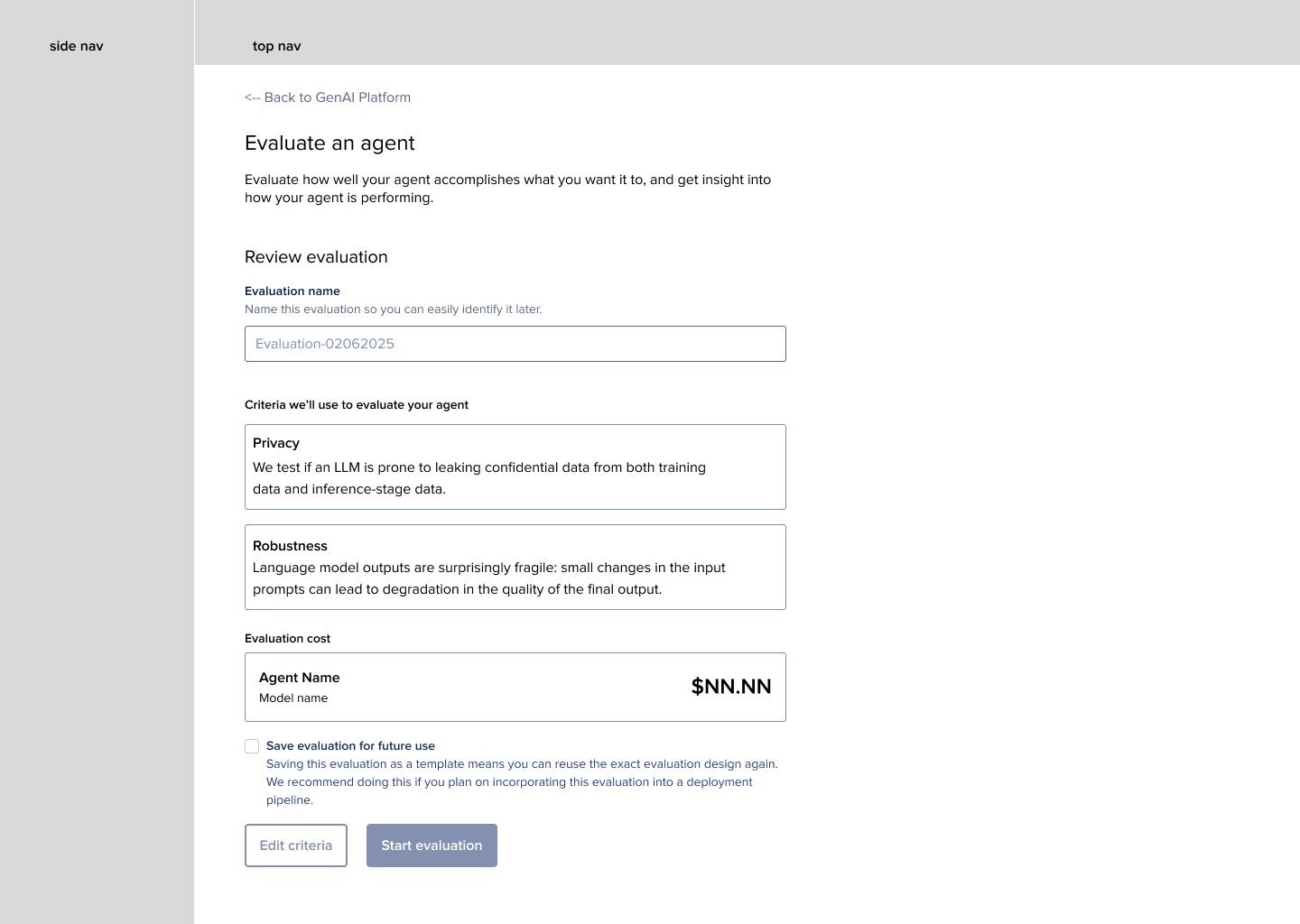
(May-ish 2025)The partner we ended up going with had 21 (but really 19) unique metrics available. In their API, users could select any combination of metrics. From the feedback we had gotten from users in previous research, and in talking to some of our internal team members who were now using this platform as guinea pigs for us, I still felt like “categories” of metrics was ultimately the correct way to lead users to picking metrics that mattered most to them.
Some of my top concerns were that users would pick metrics without knowing what they were useful for troubleshooting, or users would pick all the metrics without realizing how expensive that evaluation run could get.
I explored happy paths for roughly six conceptual approaches to introducing metrics to users during test case creation.
Predefined categories: we don’t give users full access to individual metric picking, but have “categories” of evaluations that users can combine, e.g. “safety and security” “RAG quality” “Hallucinations”
Categories + descriptions of individual metrics: No individual metric picking but users can see explicit descriptions of every metric in each category. This one veered more towards “these are all the categories we offer but you don’t have to check a bunch of boxes”. This one included a “custom” option, where users COULD select individual metrics, or a category, or a combination of the two.
Start with questions: Switch the language style up so it’s more reflective of user questions they’d ask when deciding what they need to evaluate. Some examples are, “Is my agent giving the right answers?” “Is my agent biased?” “Is my agent prone to security breaches or leaking information?” “Is my agent hallucinating ideas in its responses?”
Design decision
Interestingly, when we surfaced these options to our small private preview set of users, we found that they preferred the Custom Test version, for a few reasons. These were folks who were here not only to run evals, but also to learn. They wanted the control to read every metric definition and determine for themselves if it was relevant or not. They didn’t want us to make decisions for them, like we would with the categorical approaches, and they definitely did not trust the “design a test case for me” because of the fear of the feedback look in editing a test case with natural language.
While this audience wasn’t fully representative of our actual audience, it was the data we had at the time. We knew that after release, when we had telemetry and usage data, we would have more data to inform how users were actually using metrics, instead of just guessing.
At this point, the evaluations concept had gone through several rounds of internal design critique, a quick and dirty usability test for content quality and structure, reviews from the DO employees who were pressure testing the partner platform while I was in design phase, and several reviews with PM, eng, and leadership.

Recommend categories: The user tells us in natural language what their evaluation goal is, and we have a custom trained small language model that translates that input into a list of recommended metrics. The user could customize by then selecting metrics manually or chatting with this SLM to refine the evaluation template.
Iteration (part II)
With the object model organized, templates roughed out, and a content strategy in place, it was time to get down to brass tacks.
The meat of the design work
With the Agent Workspaces work underway with another designer, and the evaluations work now revised to accommodate a new layer of hierarchy, I set about completing the design work. This included:
Creating a copy deck to help our tech writing team, engineers, other designers, and leaders understand the content of the evaluations experience
Troubleshooting all the weird things we didn’t realize the partner’s API didn’t do until we started getting into the nitty gritty details
Happy paths fully mocked out
Researching data visualizations for scores
Errors, edge, and corner case ideation and planning
Prototyping e2e journey for exec leadership
Illustrations, icons, empty states, loading states
Collaboration with billing team, research into pricing and packaging/COGS
Plus probably a bunch more.

The final validation step
With the evaluations product humming along, we were finally able to get some eyes on the newest layer of the user experience: LLM-generated insights and recommendations.
For some of the metrics, we not only receive a score back from the third party model used to evaluate the agent, but we also receive rationale for why the prompt and output were scored the way they were. LLM-as-judge but also LLM-as-explainer.
What I wanted to make sure was that the LLM-generated content was actually valuable to users. Just because AI provided it doesn’t mean it’s good - if anything, it can often indicate that the content is decidedly not good and needs some human feedback to be of value.
I did a super quick and dirty qualitative feedback session with a small group of users to understand what their impressions were of the LLM-generated judgements. Unsurprisingly, we found that most thought that the content was insightful but not helpful. It told the user why the score was the way it was, but not the so what… how do they improve the score? How do they troubleshoot the underlying reasons why the score was what it was?
Why this is a hard problem to solve
Our evals product is served by a third party provider, who then uses their own proprietary prompts to prompt another LLM or SLM to get metrics scores. We are just a consumer of this service provider’s APIs, so we don’t have much of a say over their prompts.
But…
We identified opportunities to improve some of the LLM-generated content, including passing more context specifically about our platform to the LLM as a part of the prompt, which can help the LLM provide recommendations for next steps specific to what users can do with our platform; reducing the length of the response so users have more crisp responses to parse through; and providing a few-shot examples for the prompt to help sway model voice, vocabulary, and tone.
Watch the platform in action
The Outcome
Users seeking a way to validate that their agent is trustworthy across multiple dimensions can now run evaluations with custom test cases against any agent.
They can view and compare scores over time as agents are updated to determine whether changes have improved or not improved agent performance. Evaluations give users access to trace data about agent model decision-making, and users can get insight into RAG pipeline performance in order to improve their datasets, knowledge base retrieval settings, and agent instructions.
User feedback has been largely positive, with agent changes coming as a result of evaluations runs. We have a long to-do list of enhancements and improvements, but the product has become a critical part of agent CI/CD for many of our production-focused agent builders.
Reflections
What invigorated me
I got to start with content
Because the partner’s UI experience was not 100% aligned with their API offering, I essentially only referenced their AI for general inspiration but barely referenced it at all. Instead, I got to start with their docs, competitive analysis of other providers on the market, feedback from users on what their needs were, and the API docs. All of this informed nearly every UI decision I made, and it was such a refreshing change of pace to get to start with content.
It was extremely technical
I not only had to understand how the actual evaluation pipeline worked, but also how every single metric was scored, the relationships between different objects in the platform object model, and how everything could go wrong. It was really fun. I love a highly technical project because it allows me to develop deep expertise, collaborate closely with my engineers, and feel genuine ownership over the design because it is truly informed by my understanding of the underlying systems.
It is a platform unto itself
The agent evaluation product (and I call it a product because it has several SKUs) is not really just a product, but an entire platform. Users create and manage multiple resources, undertake multiple complex tasks, need to track historical data, and need a communication layer. The evaluations layer also has many cross-over functions with other parts of the platform, including agent versions, traces, our RAG pipelines and tool calling chains, as well as custom LLMs that provide users insights about the evaluation outcomes.
Designing for something so large is my bread and butter. I relish the opportunities to think about the entire system, not just the individual pixels, and design an experience that is platform-oriented while still being outcome-centric.
The cutting room floor
Or maybe stuff that’ll get scoped back in :)Run comparisons
What challenged me
Lack of later-stage usability testing
While the initial phases of this effort were heavily influenced by user needs, I did not have the opportunity to do deep and impactful usability testing, as the scope of the effort was expanded significantly with the Workspaces addition to the object model and the lack of flexibility on timeline.
We were fortunate to have a small team of private beta and internal team members who were testing the platform for us while we were building, so I relied on them, as well as feedback from our partner on their own user data, to help fill in the gaps when I needed eyes on the experience outside of the design team.
I was consoled by the fact that this was the type of experience that could easily be tracked - there are so many datapoints we can gather, not only about metrics usage, but about agent score performance over time, number and types of changes made after evaluations, dataset shape and strategy - that I knew I’d soon have tons of data to parse through to make improvements.
The late-phase information re-architecture
Changing the entire object model of a platform that has existed for 10 months is complex; doing it (and also, a rebrand!) while neck-deep in a massive design and engineering effort, mere months before our GA release and announcement was outright bonkers.
I was disappointed that I didn’t get as much time to really think deeply about the impacts the new information architecture would have on future roadmap items, but as designers, we just have to do our best.
So that’s what I did.
Synthetic dataset generation sources
Charts n’at